
Úvod do neuronových sítí#
Motivace - fungování mozku, propojení množství neuronů, aktivace $y$ (aktivační potenciál)
$$ y = f(\sum_{i=1}^{N}{w_i x_i + b}) $$
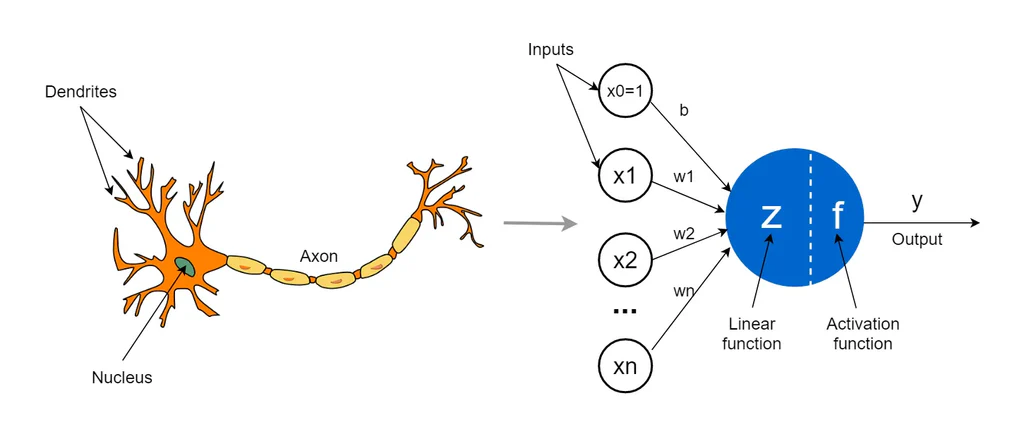
Perceptron#
Demo: https://playground.tensorflow.org/
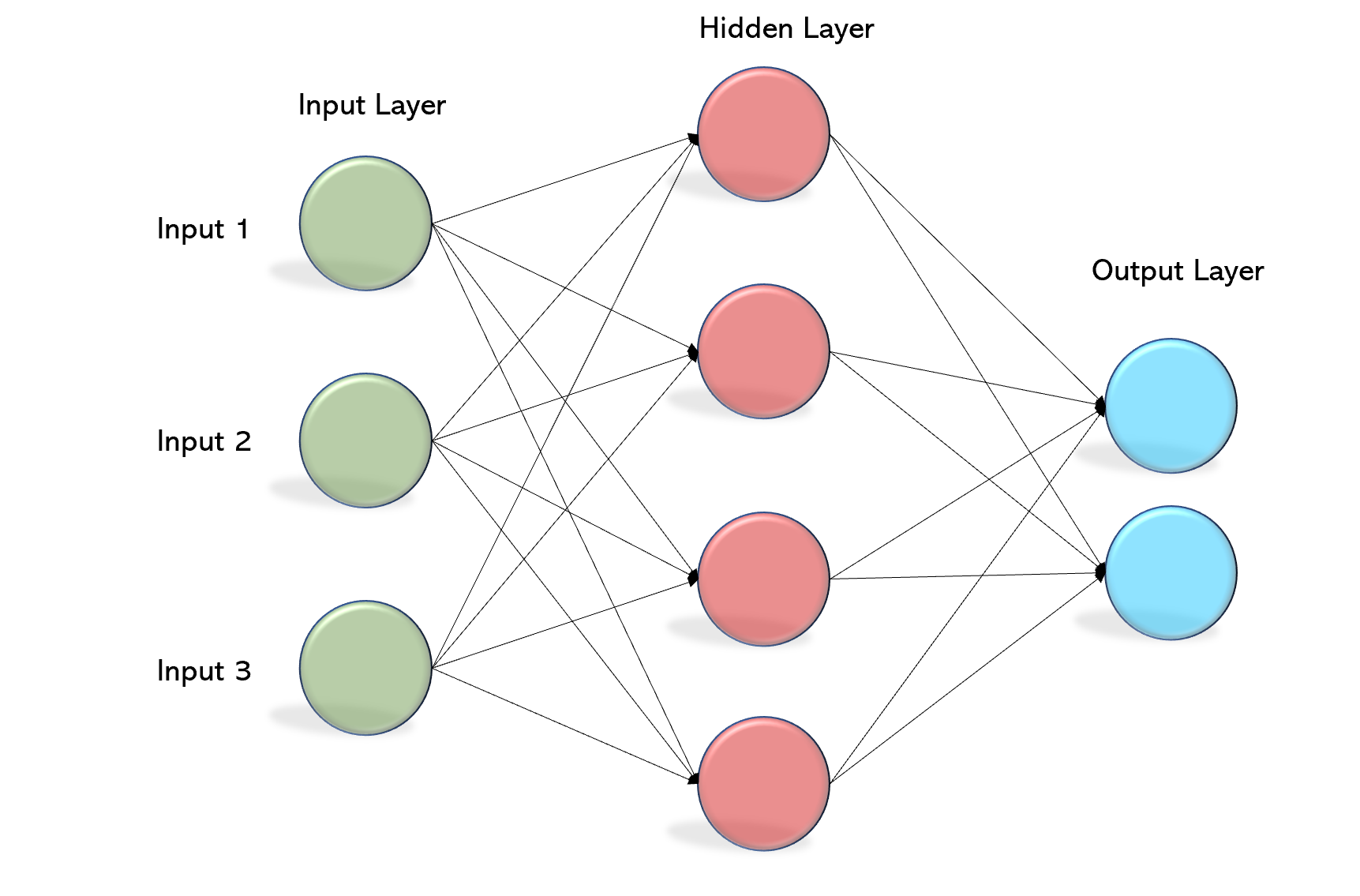
Základní architektura neuronové sítě. Skládá se z několika vrstev neuronů - vstup, výstup + skryté vrstvy:
V sousedních dvou vrstvách je každý neuron z jedné vrstvy propojen s každým z druhé vrstvy.
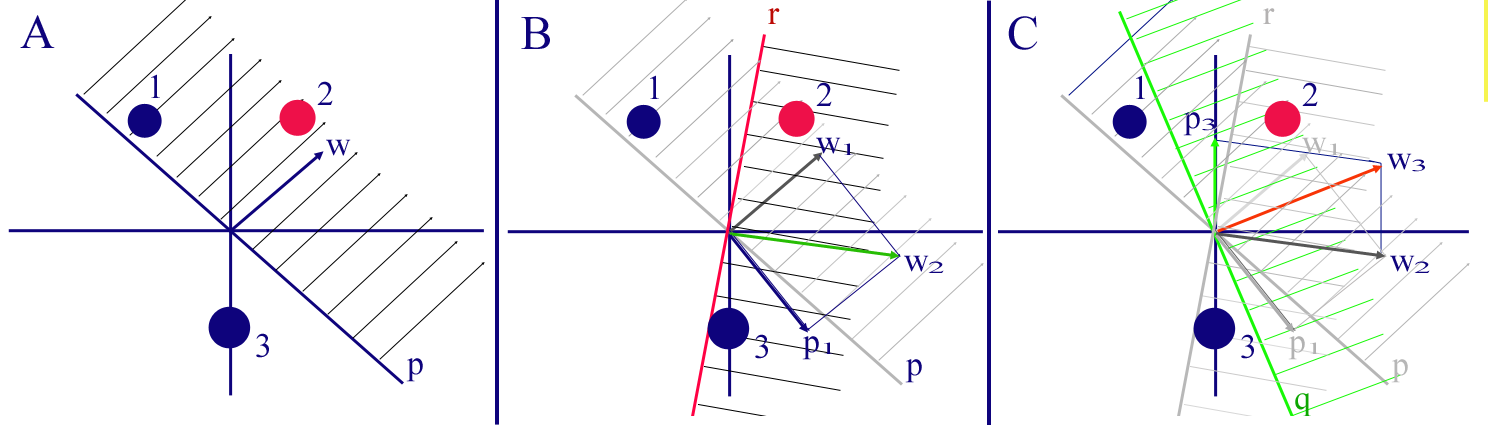
Trénování jednoduchého perceptronu:
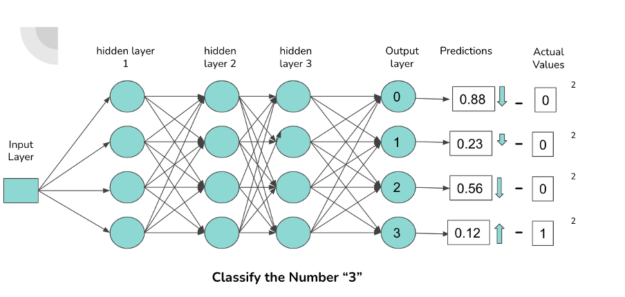
Trénování hlubokých neuronových sítí:
Pomocí optimalizačních metod + Zpětné šíření změny (Backpropagation) skrz neuronovou síť:
Metoda stochastického nejvetšího spádu
Adam, …
Učení s učitelem vs bez učitele
Chyba na výstupu se dá vizualizovat jako křivka/funkce, u které hledáme minimum - model se dopustí nejmenší chyby.
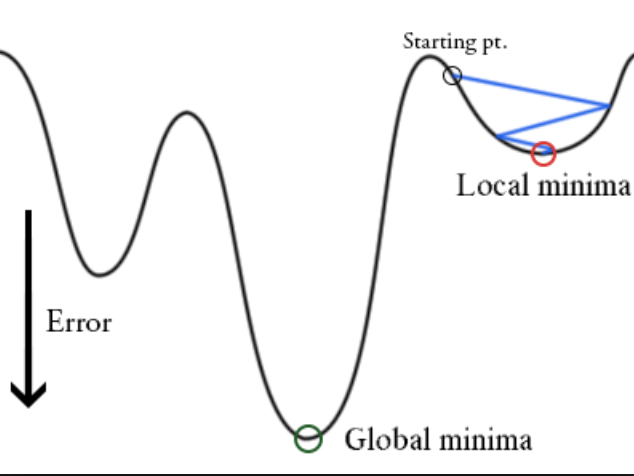
Důležité parametry pro trénování neuronových sítí:
learning rate - rychlost učení, “síla” opravy chyby na výstupu při backpropagaci
batch training - současné vyhodnocení výstupu pro více vstupů najednou, urychlení trénování
epochy - kolikrát model “viděl” všechna data, často je potřeba několik epoch pro získání přesného modelu
aktivační funkce - lineární vs nelineární: sigmoid, tanh, ReLU
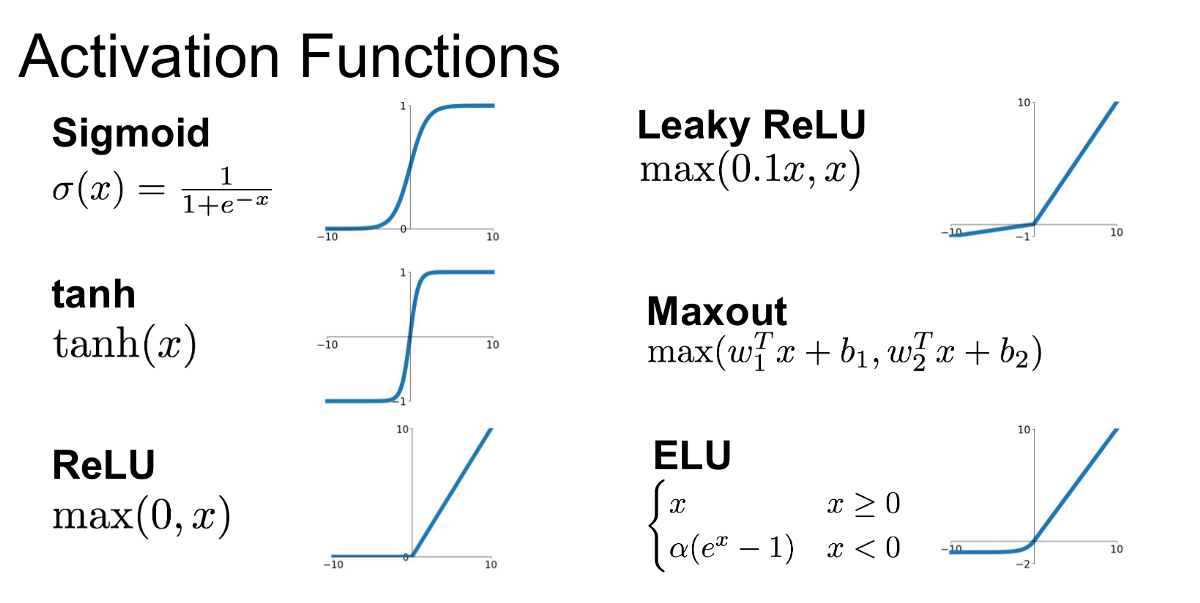
Problém učení pro hluboké sítě:
problém s explodujícími a mizejícími gradienty - čím je neuronová síť hlubší, tím náročnější je trénování a pomalejší šíření změn zpět od výstupu
Pokročilé techniky pro efektivní trénování hlubokých neuronových sítí:
dropout vrstva - při průchodu neuronovou sítí se ve zvolené vrstvě dočasně vypne zvolená část neuronů; umožnuje lépe prozkoumávat terén celkové chyby a zefektivnit učení
batch normalisation
…
Konvoluční neuronové sítě#
Demo: https://cs.stanford.edu/people/karpathy/convnetjs/demo/mnist.html
Motivace:
Vylepšení perceptronu
Zahrnutí základní vlastnosti obrázků přímo do architektury modelu - nezávislost posunutí objektu v obrázku (pořád stejný obraz)
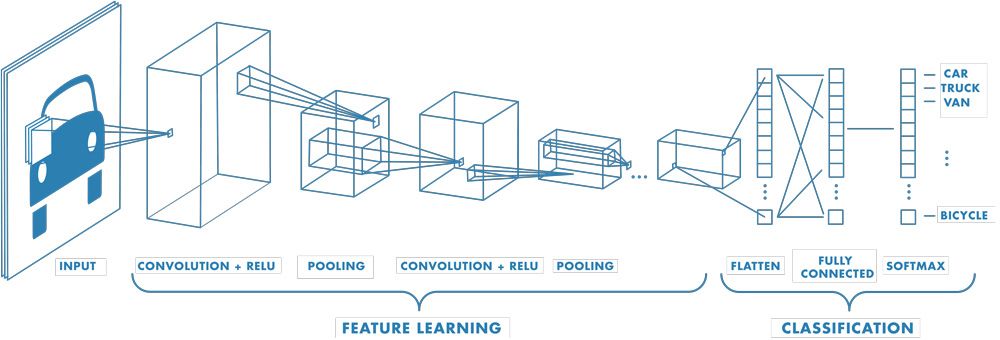
Již poměrně hluboké sítě - potřeba aplikovat pokročilé techniky trénování.
Parametry konvoluční sítě:
velikost okna (kernel size)
počet kanálů (channels) - určuje, kolik vlastností se v dané vstvě z obrázku extrahuje
max-pooling - speciální mezivrstva, která redukuje množství informace - průměrování okolních pixelů
One-hot-encoding#
Label encoding: “red” = 1, “blue” = 2, “green” = 3
one-hot encoding: “red” = (1,0,0), “blue” = (0,1,0), “green” = (0,0,1)
Pokud se data dělí do jasně odlišných a nezávislých tříd, je one-hot kódování výhodné (potřeba) a může významě zlepšit efektivitu neuronového sítě!
Specialita:
Metody word2vec - pokročilé metody kódování slov na vektorovou reprezentaci
Rekurentní neuronové sítě#
Motivace - sekvenční data, obsahující závislosti mezi sousedními prvky
Příklady - časově závislé sekvence, text
Příklad změny významu v textu:
The cat chased the mouse.
The mouse chased the cat.
Mění se délka sekvence - problém pro konvenční (feed-forward) NN architektury.
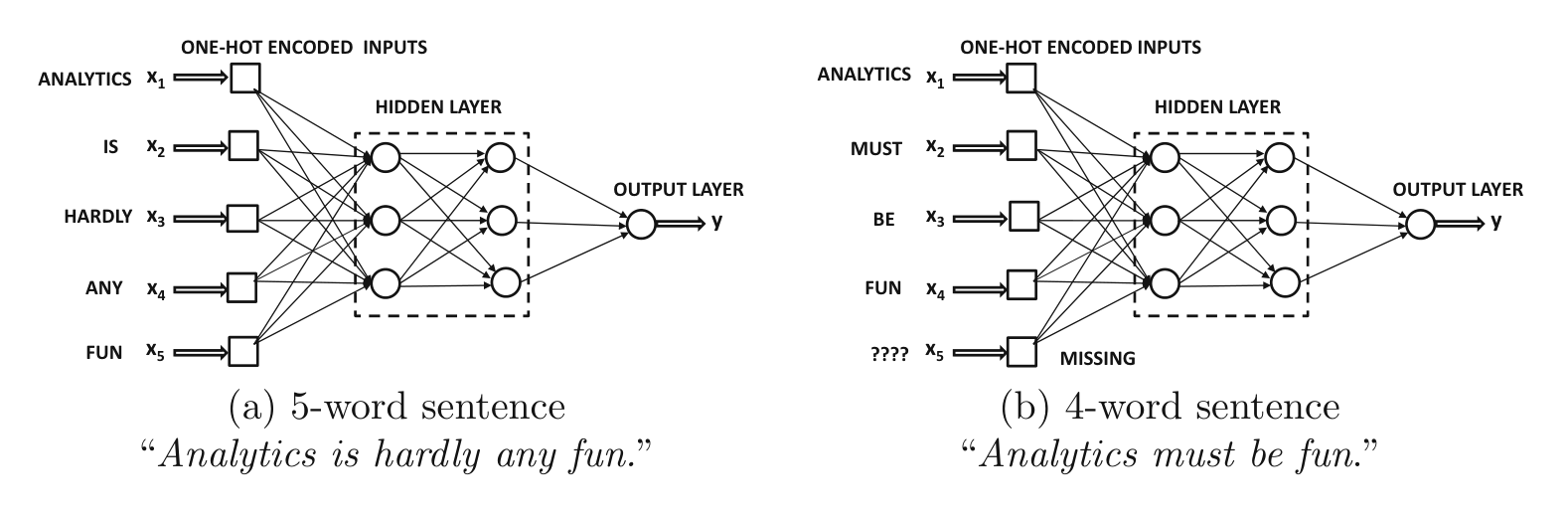
Potřeba zakódovat informaci o pořadí slov (tokenů) přímo v architektuře neuronové sítě.
Rekurentní NN:#
umožňují zpracovat vstup ve správném pořadí
ukládájí informaci o předcházejících vstupech
umožňují vkládat vstup různých délek
nekteré vstupy/výstupy můžou chybět - překlad řeči, klasifikace, atd..
Turing complete = umožňují simulovat libovolný algoritmus! (při poskytnutí dostatku dat..)
Backpropagation through time - RNN se učí opakovanou backpropagací v čase
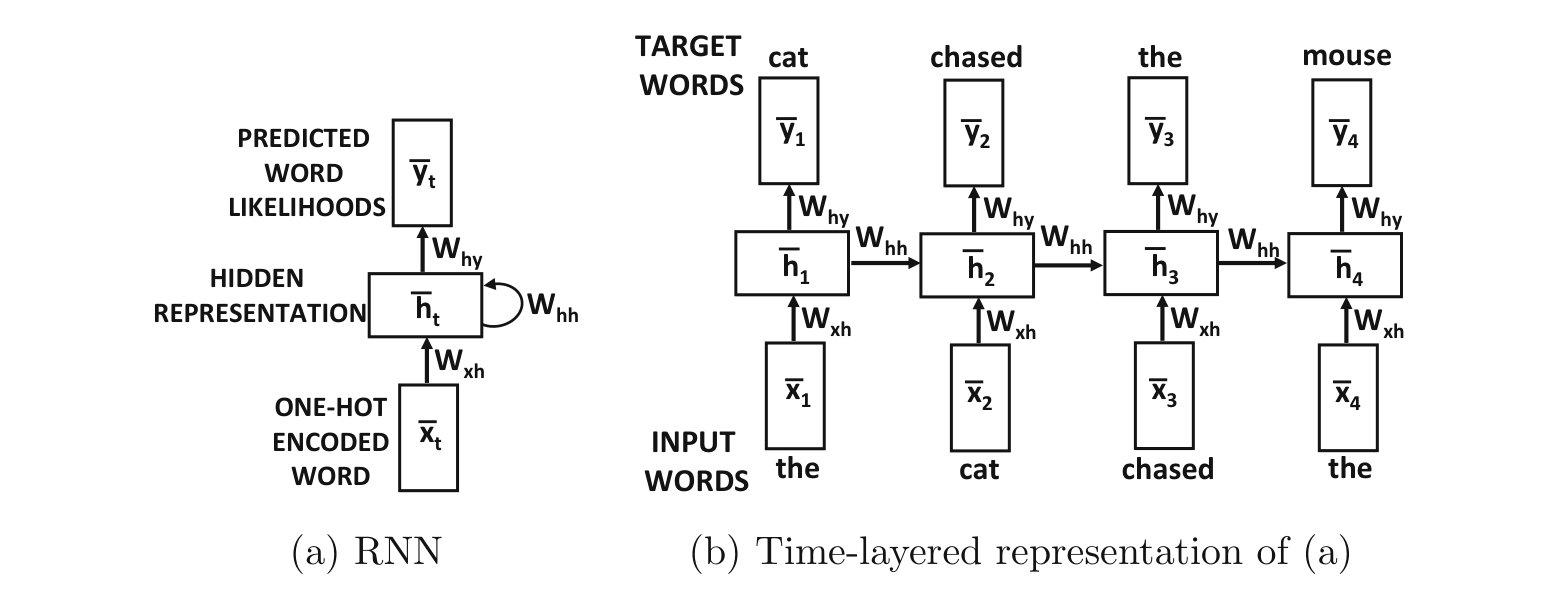
Dvě možnosti pro text:
word-level RNN - jako token/prvek volíme slovo
character-level RNN - jako token/prvek volíme znak
Word Embedding:#
první vrstva přenáší (kóduje) slovo/token do vnitřní reprezentace RNN
po sobě jdoucí slova jsou zakódovany aktivací skrytých neuronů
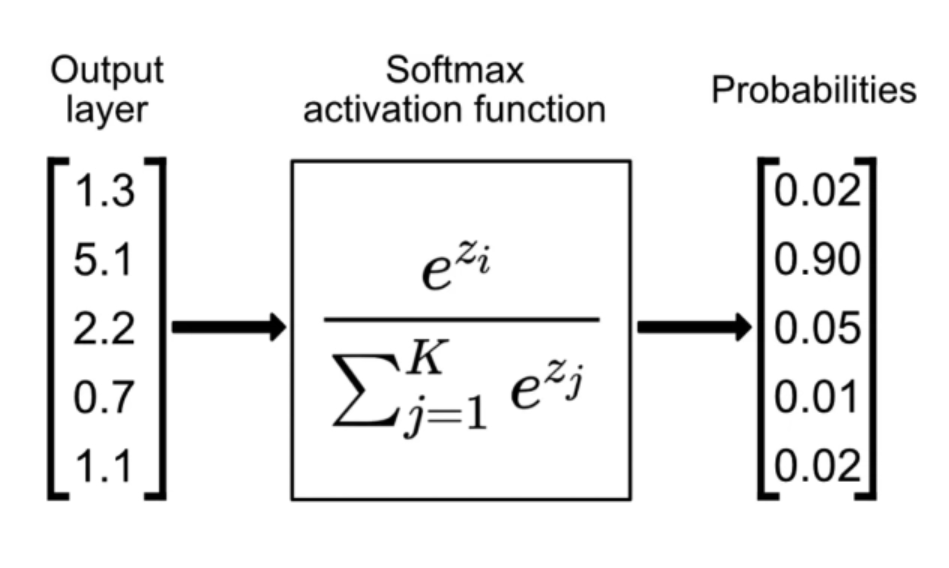
One-hot encoding:#
umožnuje reprezentovat slova/tokeny jako pravděpodobnosti
natrénovanou RNN lze škálovat - ovlivnit “jak moc si vymýšlí” nebo jak moc se řídí tím, co se naučila
softmax aktivační funkce na výstupu
Teplota - škálování výstupu#
zavedení “teploty” a pokročilejšího výběru znaku z pravděpodobností na výstupu
snadný trik - modifikace softmax aktivační funkce přidání parametru $T$
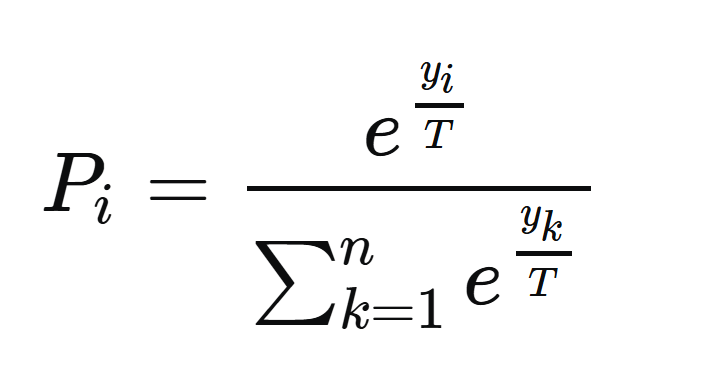
Pokročilé rekurentní NN:#
problém s explodujícími a mizejícími gradienty - čím je neuronová síť hlubší, tím náročnější je trénování a šíření sekvenční informace
dvě řešení:
LSTM - Long Short-Term Memory
GRU - Gated Recurrent Unit
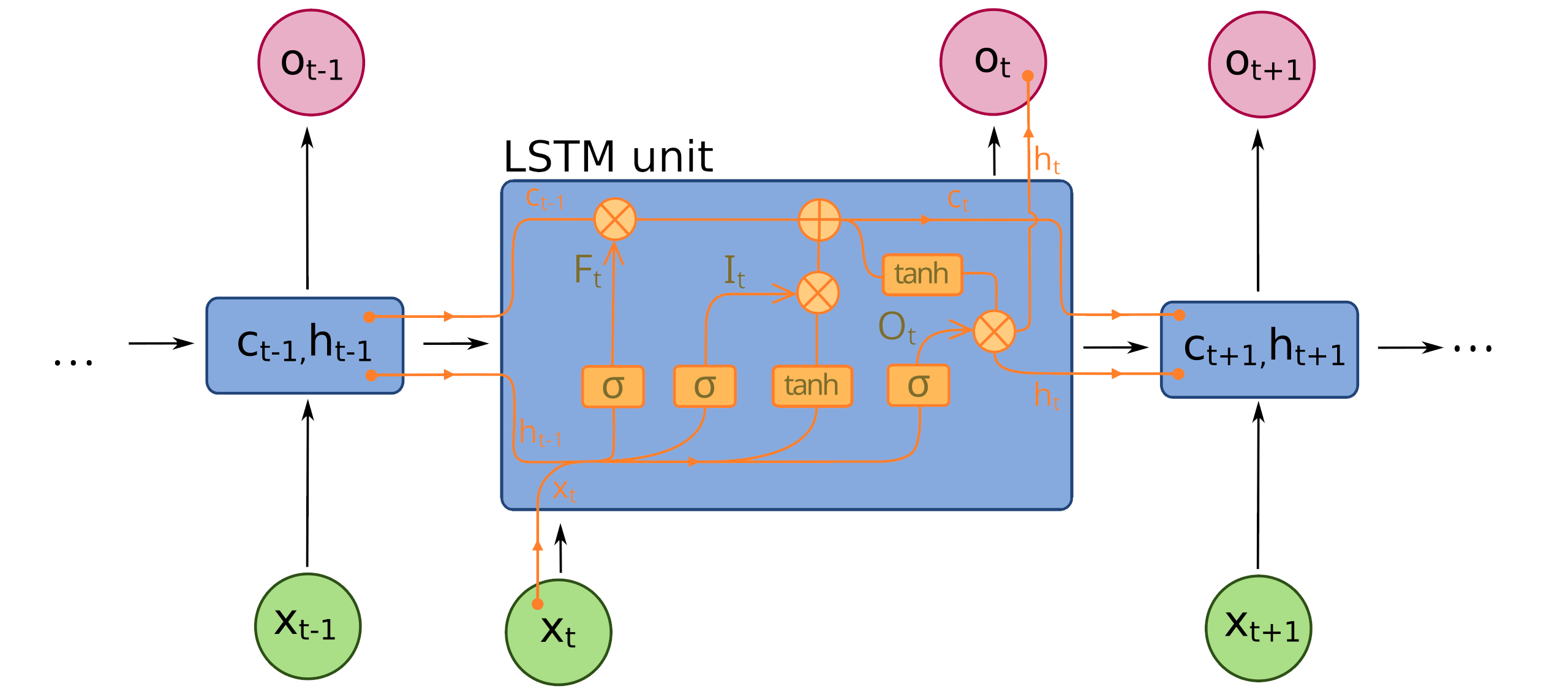
LSTM#
Jednoduché RNN si efektivně pamatují informaci pouze pro krátké řetězce (short-memory). LSTM architektura je vytvořená tak, aby prodloužila tuto “krátkou pamět” a umožnila efektivní učení vzájemných i pro dlouhé řetezce slov/tokenů. Je to dosaženo přidáním dalšího long-term skrytého stavu $c_t$ spolu s mechanismem pomalého zapomínání a přidávání nové informace.
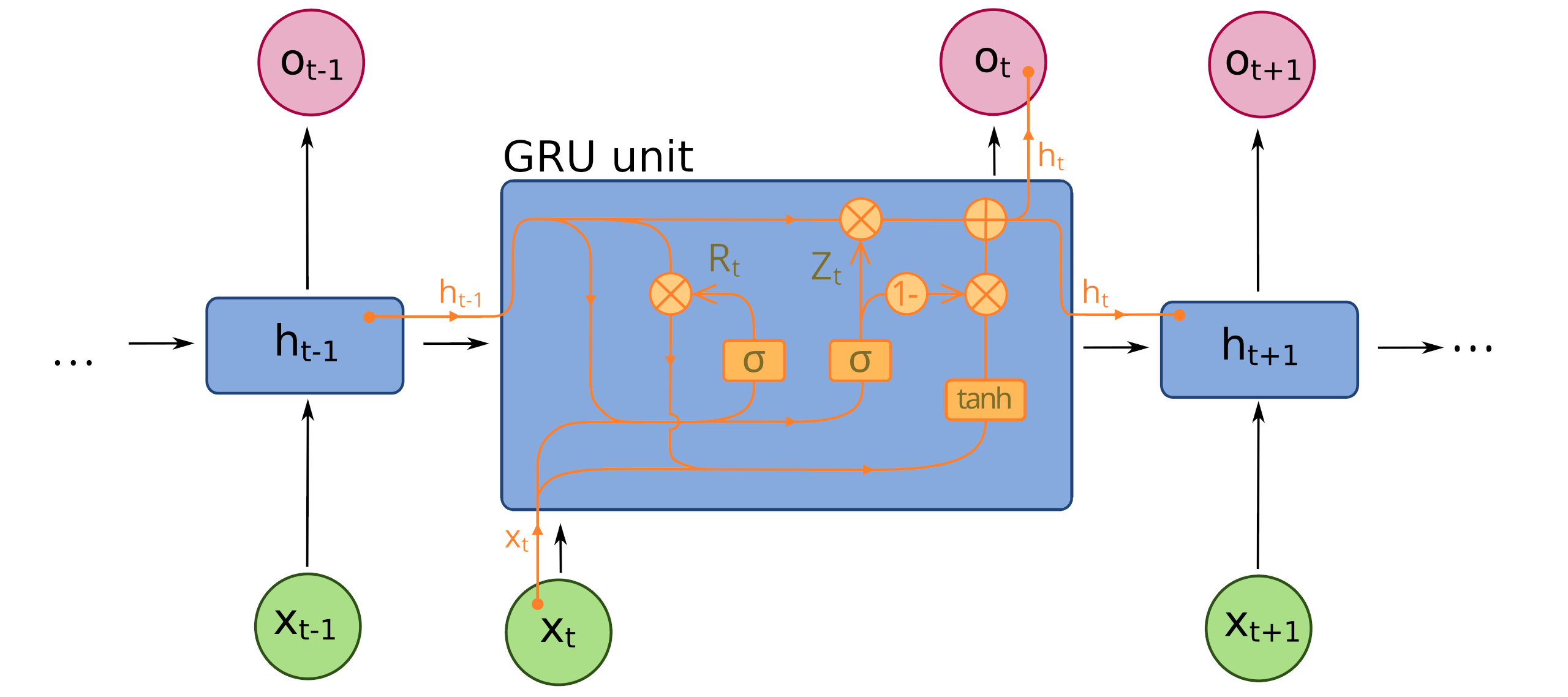
GRU#
Podobná architektura jako LSTM, ale jiný mechanismus dlouhodobé paměti.
ChatGPT a jiní chatboti#
TODO: stručný uvod/okenko do teorie chatbotu
Zdroje#
Aggarwal - Neural Networks and Deep Learning
https://eclass.upatras.gr/modules/document/file.php/EE935/%CE%97%CE%BB%CE%B5%CE%BA%CF%84%CF%81%CE%BF%CE%BD%CE%B9%CE%BA%CE%AC%20%CE%92%CE%B9%CE%B2%CE%BB%CE%AF%CE%B1/2018_Book_NeuralNetworksAndDeepLearning.pdf
Kam dál?#
https://cs.stanford.edu/people/karpathy/convnetjs/