
2. Small-scale ChatGPT - generování textu pomocí neuronových sítí#
# For tips on running notebooks in Google Colab, see
# https://pytorch.org/tutorials/beginner/colab
%matplotlib inline
!pip install -r requirements.txt
import matplotlib.pyplot as plt
import numpy as np
import torch
# Make device agnostic code
device = "cuda" if torch.cuda.is_available() else "cpu"
device
'cuda'
device = 'cpu' # Force CPU for this example
torch.device(device)
device(type='cpu')
Příprava dat I#
Databáze evropských jmen a příjmení: https://data.europa.eu/data/datasets/5bc35259634f41122d982759?locale=cs
Složka: /datasets/Seznam křestních jmen a příjmení
Databáze českých jmen: https://mv.gov.cz/clanek/seznam-rodove-neutralnich-jmen.aspx
Složka /datasets/SeznamJmenCR
import glob
import pandas as pd
dfs = pd.read_csv('datasets/SeznamJmenCR/OpenData_-_Seznam_jmen_k_2025-05-31.csv', encoding='utf-8')
jmena_typ = dfs.iloc[:, 0]
jmena_all = dfs.iloc[:, 1]
jmena_all.shape
(11331,)
jmena_typ[:10]
0 ZENA
1 ZENA
2 ZENA
3 ZENA
4 ZENA
5 ZENA
6 ZENA
7 ZENA
8 ZENA
9 ZENA
Name: DRUH_JMENA, dtype: object
jmena_all, idx = np.unique(jmena_all, return_index=True)
jmena_typ = jmena_typ[idx]
jmena_all.shape, jmena_typ.shape
((11172,), (11172,))
jmena_all[:11] # every 150th name
array(['AADAR', 'AAGTE', 'AAI', 'AAIKE', 'AAJARAQ', 'AAJU', 'AAJUNNGUAQ',
'AAKA', 'AAKKULUK', 'AAL', 'AALIYAH'], dtype=object)
Vyčištění speciálních znaků
import string
jmena_all2 = []
# Set vocab to all utf-8 printable characters
vocab = list('`1234567890-=[];\',./*-+.~!@#$%^&*()_+{}:"|<>?')
names_length = []
for jmeno in jmena_all:
cleaned = ''.join([ch for ch in str(jmeno) if ch not in vocab])
first_seq = cleaned.split()[0] if cleaned.split() else ''
first_seq = first_seq.lower()
first_seq = first_seq[0].upper() + first_seq[1:]
jmena_all2.append(first_seq)
names_length.append(len(first_seq))
jmena_all2 = np.array(jmena_all2)
jmena_typ = np.array(jmena_typ)
len(jmena_all2)
11172
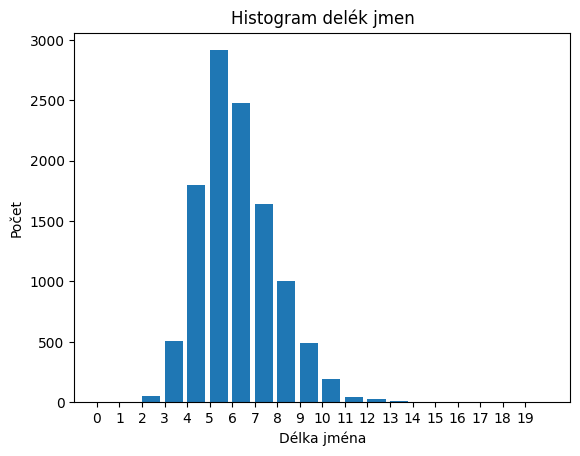
plt.hist(names_length, bins=20, range=(0,20), width=0.8)
plt.xlabel('Délka jména')
plt.ylabel('Počet')
plt.xticks(np.arange(20))
plt.title('Histogram delék jmen');
jmena_all2, idx = np.unique(jmena_all2, return_index=True)
jmena_typ2 = jmena_typ[idx]
jmena_all2.shape, jmena_typ2.shape
((11153,), (11153,))
positions = np.where(jmena_all2 == 'JAN **')[0]
print(positions)
[]
EOS = ‘\n’, START = ‘$’

# The unique characters in the file
vocab = np.array(sorted(set(''.join(jmena_all2))))
# insert special starting character
vocab = np.append(vocab,'$')
print(f'{len(vocab)} unique characters')
print(vocab)
102 unique characters
['A' 'B' 'C' 'D' 'E' 'F' 'G' 'H' 'I' 'J' 'K' 'L' 'M' 'N' 'O' 'P' 'Q' 'R'
'S' 'T' 'U' 'V' 'W' 'X' 'Y' 'Z' 'a' 'b' 'c' 'd' 'e' 'f' 'g' 'h' 'i' 'j'
'k' 'l' 'm' 'n' 'o' 'p' 'q' 'r' 's' 't' 'u' 'v' 'w' 'x' 'y' 'z' 'Á' 'Ç'
'É' 'Í' 'Ó' 'Ö' 'Ü' 'á' 'â' 'ä' 'æ' 'ç' 'é' 'ë' 'í' 'ï' 'ó' 'ô' 'ö' 'ø'
'ú' 'û' 'ü' 'ý' 'Ć' 'Č' 'č' 'ď' 'ě' 'Ľ' 'ľ' 'Ł' 'ł' 'ň' 'Ř' 'ř' 'Ş' 'ş'
'Š' 'š' 'Ť' 'ť' 'ů' 'ű' 'ź' 'ż' 'Ž' 'ž' 'ʼ' '$']
Příprava na zpracování
all_letters = ''.join(vocab)
n_letters = len(all_letters) + 1 # Plus EOS marker
all_letters
'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzÁÇÉÍÓÖÜáâäæçéëíïóôöøúûüýĆČčď켾ŁłňŘřŞşŠšŤťůűźżŽžʼ$'
names_all = jmena_all2
names_all.shape, names_all[::180]
((11153,),
array(['Aadar', 'Agamjot', 'Aldis', 'Amal', 'Anett', 'Arden', 'Atala',
'Bahşi', 'Betka', 'Brian', 'Cevin', 'Corwin', 'Darjan', 'Dion',
'Dětřich', 'Eliakim', 'Emlyn', 'Ethni', 'Feza', 'Gaby', 'Gisel',
'Hadar', 'Helmke', 'Ibolya', 'Ingrit', 'Jackson', 'Jennifer',
'Josia', 'Kamelia', 'Kerry', 'Krischna', 'Laurent', 'Lieselotta',
'Louis', 'Maaqujuk', 'Marcos', 'Matia', 'Merlijn', 'Mirabai',
'Mália', 'Nathanyel', 'Nikoletta', 'Ofir', 'Otýlie', 'Phan',
'Radouš', 'Renja', 'Rose', 'Saku', 'Selma', 'Sies', 'Sora',
'Svetislav', 'Tavi', 'Tierra', 'Tsjip', 'Uwe', 'Viki', 'Věněk',
'Yarlik', 'Zayden', 'Émilie'], dtype='<U18'))
Příprava dat II#
Databáze jmen z různých států: https://docs.pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html
from io import open
import glob
import os
import unicodedata
import string
import numpy as np
all_letters = string.ascii_letters + " .,;'-"
n_letters = len(all_letters) + 1 # Plus EOS marker
def findFiles(path): return glob.glob(path)
# Turn a Unicode string to plain ASCII, thanks to https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
# Read a file and split into lines
def readLines(filename):
with open(filename, encoding='utf-8') as some_file:
return [unicodeToAscii(line.strip()) for line in some_file]
# Build the category_lines dictionary, a list of lines per category
category_lines = {}
all_categories = []
names_all = []
names_length = []
for filename in findFiles('data/names/*.txt'):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
names_all = np.concatenate([names_all, lines])
for l in lines:
names_length.append(len(l))
n_categories = len(all_categories)
print(f'Total names count: {len(names_all)}')
if n_categories == 0:
raise RuntimeError('Data not found. Make sure that you downloaded data '
'from https://download.pytorch.org/tutorial/data.zip and extract it to '
'the current directory.')
print('# categories:', n_categories, all_categories)
print(unicodeToAscii("O'Néàl"))
Total names count: 0
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[179], line 45
42 print(f'Total names count: {len(names_all)}')
44 if n_categories == 0:
---> 45 raise RuntimeError('Data not found. Make sure that you downloaded data '
46 'from https://download.pytorch.org/tutorial/data.zip and extract it to '
47 'the current directory.')
49 print('# categories:', n_categories, all_categories)
50 print(unicodeToAscii("O'Néàl"))
RuntimeError: Data not found. Make sure that you downloaded data from https://download.pytorch.org/tutorial/data.zip and extract it to the current directory.
plt.hist(names_length, bins=20, range=(0,20), width=0.8)
plt.xlabel('Délka jména')
plt.ylabel('Počet')
plt.xticks(np.arange(20))
plt.title('Histogram delék jmen');
all_letters
"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ .,;'-"
Konstrukce neuronové sítě#
import torch
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size, hidden_size)
self.h2h = nn.Linear(hidden_size, hidden_size)
self.h2o = nn.Linear(hidden_size, output_size)
#self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.1)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, temperature = 1):
embedding = self.i2h(input)
self.hidden = self.h2h(self.hidden)
output = self.h2o(embedding + self.hidden)
#output = self.relu(output)
output = self.dropout(output)
output = self.softmax(output / temperature)
return output, self.hidden
def initHidden(self):
self.hidden = torch.zeros(1, self.hidden_size).to(device)
n_hidden = 128
rnn = RNN(n_letters, n_hidden, n_letters).to(device)
print(rnn)
RNN(
(i2h): Linear(in_features=103, out_features=128, bias=True)
(h2h): Linear(in_features=128, out_features=128, bias=True)
(h2o): Linear(in_features=128, out_features=103, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(softmax): LogSoftmax(dim=1)
)
from torchsummary import summary
rnn.initHidden()
summary(rnn, input_size=(1,n_letters), device=device)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 1, 128] 13,312
Linear-2 [-1, 128] 16,512
Linear-3 [-1, 1, 103] 13,287
Dropout-4 [-1, 1, 103] 0
LogSoftmax-5 [-1, 1, 103] 0
================================================================
Total params: 43,111
Trainable params: 43,111
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.16
Estimated Total Size (MB): 0.17
----------------------------------------------------------------
Formátování textu#
Převedení na one-hot reprezentaci
For each timestep (that is, for each letter in a training word) the
inputs of the network will be (category, current letter, hidden state)
and the outputs will be (next letter, next hidden state). So for each
training set, we’ll need the category, a set of input letters, and a
set of output/target letters.
Since we are predicting the next letter from the current letter for each
timestep, the letter pairs are groups of consecutive letters from the
line - e.g. for "ABCD<EOS>" we would create (“A”, “B”), (“B”,
“C”), (“C”, “D”), (“D”, “EOS”).

The category tensor is a one-hot
tensor of size
<1 x n_categories>. When training we feed it to the network at every
timestep - this is a design choice, it could have been included as part
of initial hidden state or some other strategy.
Zpracování textu na tokeny#
# One-hot matrix of first to last letters (not including EOS) for input
def inputTensor(line, n_letters):
tensor = torch.zeros(len(line), 1, n_letters)
for li in range(len(line)):
letter = line[li]
tensor[li][0][all_letters.find(letter)] = 1
return tensor
# ``LongTensor`` of second letter to end (EOS) for target
def targetTensor(line, n_letters):
letter_indexes = [all_letters.find(line[li]) for li in range(1, len(line))]
letter_indexes.append(n_letters - 1) # EOS
return torch.LongTensor(letter_indexes)
all_letters
'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzÁÇÉÍÓÖÜáâäæçéëíïóôöøúûüýĆČčď켾ŁłňŘřŞşŠšŤťůűźżŽžʼ$'
For convenience during training we’ll make a randomTrainingExample
function that fetches a random (category, line) pair and turns them into
the required (category, input, target) tensors.
import random
# Random item from a list
def randomChoice(l):
return l[random.randint(0, len(l) - 1)]
# Make category, input, and target tensors from a random category, line pair
def randomTrainingExample(samples_all, n_letters):
sample = randomChoice(samples_all)
input_line_tensor = inputTensor(sample, n_letters)
target_line_tensor = targetTensor(sample, n_letters)
return input_line_tensor, target_line_tensor
Trénování neuronové sítě#
criterion = nn.NLLLoss().to(device)
learning_rate = 0.0005
def train(input_line_tensor, target_line_tensor):
target_line_tensor = target_line_tensor.unsqueeze_(-1).to(device)
rnn.initHidden()
rnn.zero_grad()
loss = torch.Tensor([0]).to(device) # you can also just simply use ``loss = 0``
for i in range(input_line_tensor.size(0)):
output, _ = rnn(input_line_tensor[i].to(device))
l = criterion(output, target_line_tensor[i])
loss += l
loss.backward()
for p in rnn.parameters():
p.data.add_(p.grad.data, alpha=-learning_rate)
return output, loss.item() / input_line_tensor.size(0)
To keep track of how long training takes I am adding a
timeSince(timestamp) function which returns a human readable string:
import time
import math
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
Training is business as usual - call train a bunch of times and wait a
few minutes, printing the current time and loss every print_every
examples, and keeping store of an average loss per plot_every examples
in all_losses for plotting later.
rnn = RNN(n_letters, n_hidden, n_letters).to(device)
n_iters = 50000
print_every = 1000
plot_every = 500
all_losses = []
total_loss = 0 # Reset every ``plot_every`` ``iters``
total_loss2 = 0 # Reset every ``print_every`` ``iters``
start = time.time()
for iter in range(1, n_iters + 1):
output, loss = train(*randomTrainingExample(names_all, n_letters))
total_loss += loss
total_loss2 += loss
if iter % print_every == 0:
print('%s (%d %d%%) %.4f' % (timeSince(start), iter, iter / n_iters * 100, total_loss2 / print_every))
total_loss2 = 0
if iter % plot_every == 0:
all_losses.append(total_loss / plot_every)
total_loss = 0
0m 4s (1000 2%) 4.1481
0m 8s (2000 4%) 3.3072
0m 12s (3000 6%) 3.1127
0m 17s (4000 8%) 3.0756
0m 21s (5000 10%) 3.0282
0m 25s (6000 12%) 2.9789
0m 29s (7000 14%) 2.9759
0m 33s (8000 16%) 2.9493
0m 37s (9000 18%) 2.9006
0m 42s (10000 20%) 2.8888
0m 46s (11000 22%) 2.9065
0m 50s (12000 24%) 2.8460
0m 55s (13000 26%) 2.8500
1m 1s (14000 28%) 2.8567
1m 6s (15000 30%) 2.8452
1m 11s (16000 32%) 2.8096
1m 16s (17000 34%) 2.8131
1m 24s (18000 36%) 2.8168
1m 29s (19000 38%) 2.8321
1m 34s (20000 40%) 2.8304
1m 38s (21000 42%) 2.8150
1m 46s (22000 44%) 2.7586
1m 55s (23000 46%) 2.7725
2m 5s (24000 48%) 2.8128
2m 20s (25000 50%) 2.7393
2m 35s (26000 52%) 2.7518
2m 52s (27000 54%) 2.8036
2m 59s (28000 56%) 2.7671
3m 5s (29000 57%) 2.7698
3m 10s (30000 60%) 2.7660
3m 15s (31000 62%) 2.7677
3m 19s (32000 64%) 2.7538
3m 23s (33000 66%) 2.7335
3m 26s (34000 68%) 2.7359
3m 30s (35000 70%) 2.7188
3m 34s (36000 72%) 2.7471
3m 38s (37000 74%) 2.7451
3m 42s (38000 76%) 2.7359
3m 46s (39000 78%) 2.7130
3m 50s (40000 80%) 2.7494
3m 53s (41000 82%) 2.7259
3m 57s (42000 84%) 2.7265
4m 1s (43000 86%) 2.6923
4m 5s (44000 88%) 2.7353
4m 9s (45000 90%) 2.7293
4m 12s (46000 92%) 2.7001
4m 16s (47000 94%) 2.7237
4m 20s (48000 96%) 2.6907
4m 24s (49000 98%) 2.7159
4m 28s (50000 100%) 2.7172
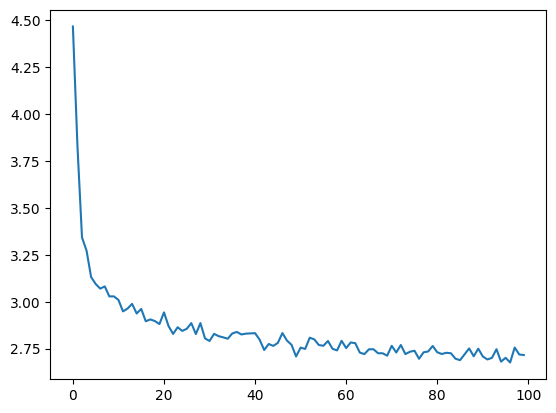
Plotting the Losses#
Plotting the historical loss from all_losses shows the network learning:
import matplotlib.pyplot as plt
plt.figure()
plt.plot(all_losses);
import datetime
dt = datetime.datetime.now().strftime('%Y%m%d%H%M%S')
print(dt)
import os
os.makedirs('results', exist_ok=True)
torch.save(rnn.state_dict(), f'results/model2_jmena_rnn_{dt}.pth')
20250623235343
rnn = RNN(n_letters, n_hidden, n_letters).to(device)
rnn.load_state_dict(torch.load('results/model2_jmena_rnn_20250623235338.pth'))
<All keys matched successfully>
Vzorkování natrénováné RNN#
To sample we give the network a letter and ask what the next one is, feed that in as the next letter, and repeat until the EOS token.
Create tensors for input category, starting letter, and empty hidden state
Create a string
output_namewith the starting letterUp to a maximum output length,
Feed the current letter to the network
Get the next letter from highest output, and next hidden state
If the letter is EOS, stop here
If a regular letter, add to
output_nameand continue
Return the final name
max_length = 20
# Sample from a category and starting letter
def sample(start_letter='A', temperature=1):
with torch.no_grad(): # no need to track history in sampling
input = inputTensor(start_letter, n_letters)
rnn.initHidden()
output_name = start_letter
for i in range(max_length):
#print(torch.exp(output.squeeze()))
if temperature != 'max': # sample from distribution
output, _ = rnn(input[0].to(device), temperature=temperature)
a = torch.arange(n_letters).to(device)
p = torch.exp(output.squeeze()) # temperature
index = p.multinomial(num_samples=1, replacement=True)
topi = a[index]
else: # max
output, _ = rnn(input[0].to(device), temperature=1)
topv, topi = output.topk(1)
topi = topi[0][0]
if topi == n_letters - 1:
break
else:
letter = all_letters[topi]
output_name += letter
input = inputTensor(letter, n_letters)
return output_name
# Get multiple samples from one category and multiple starting letters
def samples(start_letters='ABC', temperature=1):
for start_letter in start_letters:
sample_name = sample(start_letter, temperature)
txt = ' '*(22-len(sample_name))
print(f'{sample_name}{txt}| je v datasetu: ', sample_name in names_all)
#samples('ADJLHOLAD', temperature = 'max')
samples('ADJLHOLAD', temperature = 0.8)
Atanpeo | je v datasetu: False
Dlila | je v datasetu: False
Joáen | je v datasetu: False
Lodyda | je v datasetu: False
Hriseka | je v datasetu: False
Ole | je v datasetu: False
Lraney | je v datasetu: False
Aáriyk | je v datasetu: False
Derana | je v datasetu: False
Vizualizace#
!pip install torchview
from torchviz import make_dot
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files/Graphviz/bin/'
y_pred = rnn(inputTensor('A', n_letters)[0].to(device)) # Get predictions for the first training sample
make_dot(y_pred, params=dict(list(rnn.named_parameters()))).render("rnn_torchviz", format="png")
'rnn_torchviz.png'
import torchvision
from torchview import draw_graph
rnn.initHidden()
model_graph = draw_graph(rnn, input_size=(n_hidden,n_letters), expand_nested=True, device=device)
model_graph.visual_graph

Analýza aktivací neuronů ve skryté vstvě#
rnn.hidden
max_length = 20
# Sample from a category and starting letter
def sampleAnalysis(start_letter='A', temperature=1):
list_prob = []
list_hidden_states = []
with torch.no_grad(): # no need to track history in sampling
input = inputTensor(start_letter, n_letters)
rnn.initHidden()
output_name = start_letter
for i in range(max_length):
#print(torch.exp(output.squeeze()))
if temperature != 'max': # sample from distribution
output, _ = rnn(input[0].to(device), temperature=temperature)
propabilities = torch.exp(output.squeeze()) # temperature
index = propabilities.multinomial(num_samples=1, replacement=True)
list_prob.append(propabilities)
a = torch.arange(n_letters).to(device)
topi = a[index]
else: # max
output, _ = rnn(input[0].to(device), temperature=1)
topv, topi = output.topk(1)
topi = topi[0][0]
list_hidden_states.append(rnn.hidden)
if topi == n_letters - 1:
break
else:
letter = all_letters[topi]
output_name += letter
input = inputTensor(letter, n_letters)
return output_name, list_prob, list_hidden_states
# CHANGE START LETTER
start_letter = 'E'
output_name, list_prob, list_hidden_states = sampleAnalysis(start_letter, temperature = 0.8)
txt = ' '*(22-len(output_name))
print(f'{output_name}{txt}| je v datasetu: ', output_name in names_all)
Ealavke | je v datasetu: False
len(all_letters), all_letters
(102,
'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzÁÇÉÍÓÖÜáâäæçéëíïóôöøúûüýĆČčď켾ŁłňŘřŞşŠšŤťůűźżŽžʼ$')
first_cnt = 10
first_ind = [torch.topk(prob, first_cnt, dim=0).indices.numpy() for prob in list_prob]
first_prob = [prob[torch.topk(prob, first_cnt, dim=0).indices.numpy()] for prob in list_prob]
first_letters = [[all_letters[idx] if idx < len(all_letters) else 'EOS' for idx in torch.topk(prob, first_cnt, dim=0).indices.numpy()] for prob in list_prob]
zarr = np.zeros(first_cnt)
zarr[0] = 1
first_prob.insert(0, zarr)
charr = ['']*(first_cnt-1)
charr.insert(0,start_letter)
first_letters.insert(0, charr)
#first_ind, first_prob, first_letters
list(output_name)
['E', 'a', 'l', 'a', 'v', 'k', 'e']
Hodnoty aktivace pro konkrétní neuron ve skryté vrstvě
neur_idx = 1
list_hidden_states = np.array(list_hidden_states).squeeze()
hidd_states = list_hidden_states[:,neur_idx]
hidd_states = np.insert(hidd_states, 0, 0)
hidd_states
array([ 0. , -0.07578509, -0.36010897, -0.91851234, -1.336549 ,
-1.524146 , -1.6372837 , -1.7838877 ], dtype=float32)
np.insert(first_prob, 0, 0, axis=0)
array([[0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ],
[1. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ],
[0.20061983, 0.14512566, 0.08226797, 0.07782461, 0.07158079,
0.06108891, 0.05420543, 0.05408461, 0.02366396, 0.02159487],
[0.26792637, 0.24500218, 0.07636154, 0.05460576, 0.04006299,
0.03544253, 0.03368717, 0.0286148 , 0.02182723, 0.01881991],
[0.23897254, 0.20944875, 0.20298781, 0.0515274 , 0.03509137,
0.03126996, 0.0261696 , 0.02332604, 0.02142181, 0.01904682],
[0.59442061, 0.07859479, 0.04832272, 0.044892 , 0.02730436,
0.01680035, 0.01647219, 0.01464469, 0.01440912, 0.0118991 ],
[0.31559131, 0.27130988, 0.16887985, 0.08487671, 0.01854577,
0.01736904, 0.01531465, 0.01238602, 0.00870397, 0.00734951],
[0.37546197, 0.37028736, 0.14048098, 0.03405308, 0.01228636,
0.01109617, 0.00748526, 0.00579284, 0.00558276, 0.00349378],
[0.74166256, 0.09109943, 0.02465235, 0.0198315 , 0.01960669,
0.01142026, 0.01015497, 0.00668037, 0.00582328, 0.00546245]])
import numpy as np
import matplotlib.pyplot as plt
hidden_neur_cnt = 10
# Select hidden_neur_cnt random unique indices from 0 to list_hidden_states.shape[1] - 1
#np.random.seed(42)
hidden_indices = np.random.choice(list_hidden_states.shape[1], hidden_neur_cnt, replace=False)
list_hidden_states = np.array(list_hidden_states.squeeze())
hidd_states = list_hidden_states[:,hidden_indices]
hidd_states = np.insert(hidd_states, 0, 0, axis=0)
hidd_states = np.insert(hidd_states, 0, 0, axis=0).T
# Convert first_prob tensors to numpy arrays for easier handling
#probs = [p.detach().cpu().numpy() for p in first_prob]
probs = np.insert(first_prob, 0, 0, axis=0)
#probs = first_prob
#print(len(probs))
first_lett = np.insert(first_letters, 0, '', axis=0)
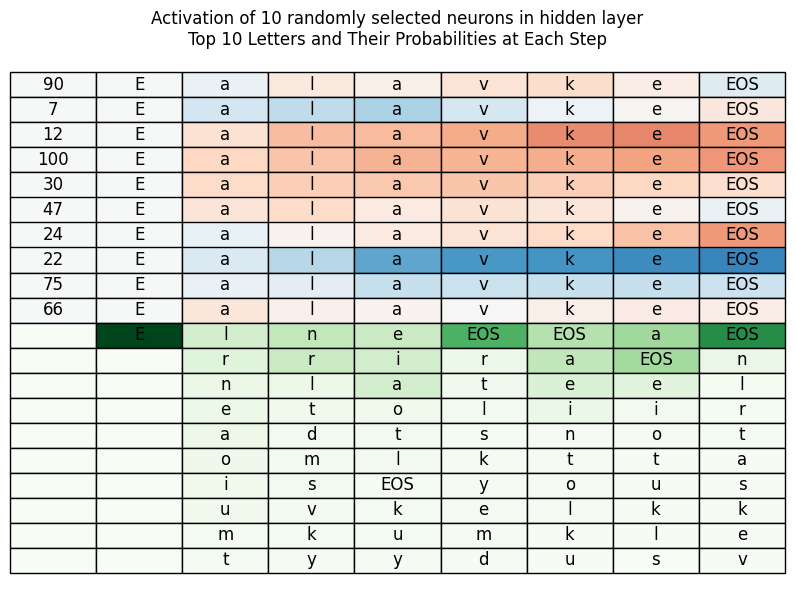
# Create a table of letters and their probabilities
table_data = []
for i in range(first_cnt):
row = []
for step in range(len(first_lett)):
if i < len(first_lett[step]):
row.append(first_lett[step][i])
else:
row.append('')
table_data.append(row)
for ni in range(hidden_neur_cnt):
table_data.insert(0, [hidden_indices[ni]] + list(output_name) + ['EOS'])
# Create a table of probabilities for coloring
prob_data = []
# Add the output_name as the first row in the table
for i in range(first_cnt):
row = []
for step in range(len(probs)):
if i < len(probs[step]):
row.append(probs[step][i])
else:
row.append(0)
prob_data.append(row)
# Plot the table
fig, ax = plt.subplots(figsize=(10, 4+hidden_neur_cnt//3))
table = ax.table(cellText=table_data,
cellLoc='center',
loc='center')
# Normalize hidd_states for coloring the first row
hidd_states_norm = (torch.sigmoid(torch.tensor(hidd_states)).numpy())
print(hidd_states_norm)
# Create a colormap for the first row (e.g., Blues)
first_row_colors = plt.cm.RdBu(hidd_states_norm)
# Prepare the rest of the cell colors using prob_data (skip the first row)
prob_colors = plt.cm.Greens(np.array(prob_data))
# Combine first row and the rest
cell_colours = np.vstack([first_row_colors, prob_colors])
# Set the cell colors
for i in range(len(cell_colours)):
for j in range(len(cell_colours[i])):
table[(i, j)].set_facecolor(cell_colours[i, j])
table.auto_set_font_size(False)
table.set_fontsize(12)
table.scale(1, 1.5) # width, height scaling; 1.5*10=15px height per row if default is 10
ax.axis('off')
ax.set_title('Activation of 10 randomly selected neurons in hidden layer\nTop 10 Letters and Their Probabilities at Each Step')
plt.show()
[[0.5 0.5 0.5337876 0.4499274 0.47020406 0.43090636
0.4123119 0.4638193 0.5633949 ]
[0.5 0.5 0.5908886 0.6284456 0.6582888 0.5871348
0.5293862 0.4935395 0.44581416]
[0.5 0.5 0.42193493 0.34559494 0.3420299 0.3136924
0.26444465 0.25478578 0.284875 ]
[0.5 0.5 0.39777896 0.35573307 0.3272938 0.33072612
0.31852686 0.3003137 0.2807517 ]
[0.5 0.5 0.40311497 0.37730387 0.3650653 0.36179906
0.37671608 0.39607164 0.41503328]
[0.5 0.5 0.4354283 0.40262616 0.45514223 0.4289041
0.43952554 0.48405614 0.534953 ]
[0.5 0.5 0.5419657 0.4866691 0.45652497 0.43198037
0.40281287 0.35420954 0.28416175]
[0.5 0.5 0.57663214 0.6413209 0.7619112 0.7895
0.7979874 0.81531996 0.8293918 ]
[0.5 0.5 0.53403956 0.5513421 0.61676633 0.61255175
0.6162941 0.6155658 0.60621876]
[0.5 0.5 0.43858436 0.47428122 0.4865652 0.49909398
0.47106516 0.4607258 0.46249813]]
Zdroje#
https://karpathy.github.io/2015/05/21/rnn-effectiveness/
https://docs.pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html
https://www.tensorflow.org/text/tutorials/text_generation