Metody lineární algebry#
import numpy as np
import scipy.linalg as la
import matplotlib.pyplot as plt
Základní operace s maticemi#
Skalární součin#
Skalární součin dvou vektorů \( \vec{x} \in \mathbb{R}^{n} \) a \( \vec{y} \in \mathbb{R}^{n} \) je definován následovně:
Napište funkci, která počítá skalární součin dvou vektorů. Nepoužijte žádné knihovní funkce (np.dot() nebo operátoru @). Zkontrolujte správnost pomocí vhodné knihovní funkce.
Pro získání rozměrů matice nebo vektoru můžete použít
x.shape,A.shape[i](velikost v i-tém směru) nebonp.shape(A)[i].Pro procházení dvou polí najednou lze použít konstrukce
for (xi,yi) in zip(x,y):.Nový vektor vytvářejte pomocí
np.zero().
x = np.random.rand(3)
y = np.random.rand(3)
print(x,y)
def skalarni_soucin(x, y):
## DOPLŇTE ##
s = 0
for i in range(len(x)):
s += x[i]*y[i]
return s
print(skalarni_soucin(x,y), np.dot(x,y))
[0.52308803 0.6488837 0.10499606] [0.84737369 0.98112284 0.19972114]
1.1008555848590889 1.1008555848590889
Součin matice s vektorem#
Součin matice \( \mathbb{A} \in \mathbb{R}^{m \ \times \ n} \) a vektoru \( \vec{x} \in \mathbb{R}^{n} \) je definován následovně:
Napište funkci, která počítá součin matice s vektorem. Nepoužijte žádné knihovní funkce (np.dot() nebo operátoru @). Zkontrolujte správnost pomocí vhodné knihovní funkce. Lze využít předchozí funkci skalarni_soucin().
A = np.random.rand(3,4)
x = np.random.rand(4)
print(A,x)
def soucin_matice_vektor(A, x):
## DOPLŇTE ##
y = np.zeros(shape=A.shape[0])
for i in range(A.shape[0]):
for j in range(A.shape[1]):
y[i] += A[i,j]*x[j]
return y
print(soucin_matice_vektor(A,x), np.dot(A,x))
[[0.05825235 0.88253031 0.67351158 0.7373078 ]
[0.82912453 0.85221701 0.2107315 0.37011322]
[0.31115322 0.93188241 0.82415044 0.82859453]] [0.21975059 0.73564375 0.43081856 0.68127001]
[1.45449587 1.1520628 1.67346548] [1.45449587 1.1520628 1.67346548]
Součin matice s maticí#
Součin dvou matic \( \mathbb{A} \in \mathbb{R}^{m \ \times \ n} \) a \( \mathbb{B} \in \mathbb{R}^{n \ \times \ p} \) je definován následovně:
Napište funkci, která počítá součin dvou matic. Nepoužijte žádné knihovní funkce (np.dot() nebo operátoru @). Zkontrolujte správnost pomocí vhodné knihovní funkce.
A = np.random.rand(3,4)
B = np.random.rand(4,3)
print(A)
print(B)
def soucin_matic(A, B):
## DOPLŇTE ##
C = np.zeros(shape=[A.shape[0], B.shape[1]])
for i in range(A.shape[0]):
for j in range(B.shape[1]):
for k in range(A.shape[1]):
C[i,j] += A[i,k]*B[k,j]
return C
print(soucin_matic(A,B))
print(np.dot(A,B))
[[0.93357651 0.87021682 0.45216851 0.97503516]
[0.44289134 0.17582117 0.66793537 0.45632162]
[0.89402771 0.71398108 0.98519966 0.11308755]]
[[0.43728347 0.64764467 0.85710192]
[0.46045173 0.5767902 0.00613036]
[0.46301383 0.30221798 0.43546692]
[0.67217759 0.57220078 0.45733491]]
[[1.67368747 1.80112771 1.44832701]
[0.89061871 0.85121781 0.88023644]
[1.25187335 1.35328341 1.25139058]]
[[1.67368747 1.80112771 1.44832701]
[0.89061871 0.85121781 0.88023644]
[1.25187335 1.35328341 1.25139058]]
K snadnějšímu otestování správnosti lze použít následující funkci, která porovná výsledeky na zvolený počet míst:
try:
np.testing.assert_array_almost_equal(soucin_matic(A, B), np.dot(A, B), decimal=7)
except AssertionError as E:
print(E)
else:
print("The implementation is correct.")
The implementation is correct.
Řešení soustavy lineárních rovnic#
Hlavní úlohou lineární algebry je řešení soustavy rovnic. Tuto úlohu dokáže počítač řešit stejně jako člověk, jelikož jsou známy algoritmy s konečným počtem kroků. Stačí tedy provést konečný počet aritmetických operací s konečným počtem čísel.
Jelikož tento typ lze snadno řešit na počítači, často se jiné úlohy převádí právě na soustavu lineárních rovnic, kterou dokážeme řešit. Příkladem tohoto postupu je řešení obyčejných diferenciálních rovnic (ODR) nebo parciálních diferenciálních rovnic (PDR), se kterými se setkáme v poslední kapitole.
Matematicky můžeme problém zapsat následovně:
Metody řešící soustavu lineárních rovnic můžeme rozdělit do tří skupin:
Metody přímé - přímý běh s daným počtem kroků podle velikosti matice
Metody iterační - postupné zpřesňování výsledku
Metody optimalizační - minimalizace funkce \(|\mathbb{A}\vec{x} - \vec{b}|\) gradientími metodami (viz kapitola 8)
Přímé metody pro řešení soustavy lineárních rovnic#
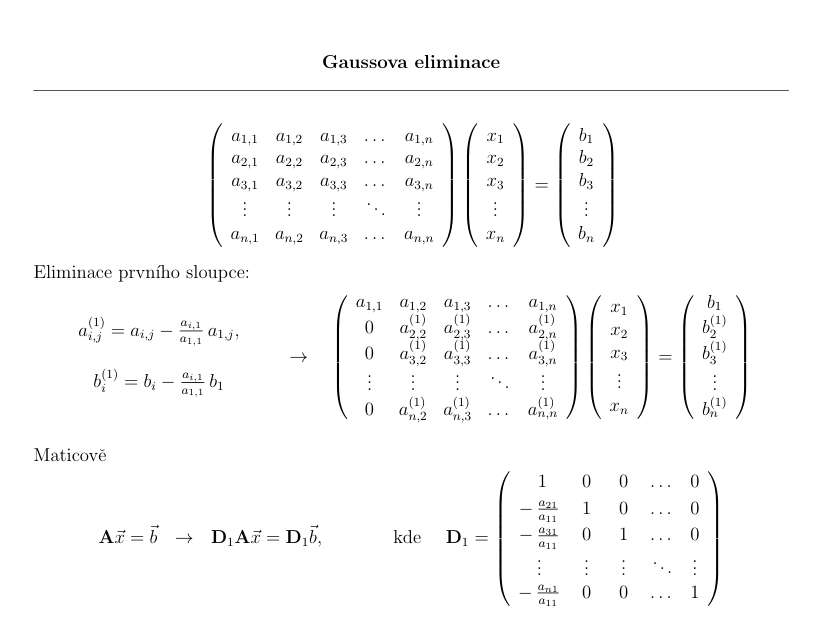
Gaussova eliminace#
Gaussova eleminace je algoritmus, který transformuje libovolnou matici na horní (nebo dolní) trojúhelníkovou. To výrazně zjednodušší celou soustavu. Řešení pak lze spočítat pomocí tzv. zpětného běhu. Jednotlivé kroky celého algoritmu si zde ukážeme.
Je to vlastně zobecněný postup eliminace členů v soustavě rovnic. Podobný postup známe již ze střední - sčítání/odčítání rovnic s cílem eliminovat dostatek členů tak, abychom mohli postupně vyjádřit a spočítat jednotlivé složky řešení.
Dopředný běh
Matici \( \mathbb{A} \in \mathbb{R}^{n \ \times \ n} \) je možné transformovat na horní trojúhelníkovou pomocí vzorce:
Implementujte Gaussovu eliminaci, tedy převedení libovolné matice na horní trojúhelníkovou, pomocí uvedeného vzorce. Jaká je složitost celého algoritmu?
Dejte si pozor na nechtěné přepsání hodnoty \(a_{ji}\), která je potřeba k aktualizaci celého řádku!
A = np.random.rand(4,4)
b = np.random.rand(4)
print(A, b)
def gauss_elim_dopredna(A, b):
A = A.copy()
b = b.copy()
## DOPLŇTE ##
for i in range(A.shape[0]):
for j in range(i+1,A.shape[0]): # indexy [i+1,n-1]
a = A[j,i]
for k in range(i,A.shape[1]): # zde staci prochazet indexy [i,n-1]
A[j,k] -= a / A[i,i] * A[i,k]
b[j] -= a / A[i,i] * b[i]
return A,b
B,_ = gauss_elim_dopredna(A,b)
print(B)
[[0.7600714 0.37391487 0.86619317 0.76120054]
[0.50700822 0.15162721 0.6256598 0.90929201]
[0.47386776 0.94428231 0.29844483 0.84632607]
[0.73167447 0.27600311 0.67959443 0.047184 ]] [0.96161125 0.81673387 0.53325112 0.07487286]
[[ 0.7600714 0.37391487 0.86619317 0.76120054]
[ 0. -0.09779398 0.0478627 0.4015306 ]
[ 0. 0. 0.10647607 3.29171208]
[ 0. 0. 0. 5.00809857]]
Předchozí implementace lze zjednodušit při použití řezání polí. Zde pro názornost používáme for-cykly. Díky tomu je snadno vidět, že složitost algoritmu je \(O(N^3)\).
Zpětný běh
Soustava lineárních rovnic \( \mathbb{A} x = b \) s horní trojúhelníkovou maticí \( \mathbb{A} \in \mathbb{R}^{n \ \times \ n} \) je možné vyřešit pomocí zpětné substituce neboli zpětného běhu Gaussovy eliminace:
Implementujte zpětný běh Gaussovy eliminace, tedy řešení soustavy lineárních rovnic s trojúhelníkovou maticí, pomocí uvedeného vzorce. Správnost ověřte pomocí knihovní funkce scipy.linalg.solve().
A = np.triu(np.random.rand(4, 4)) # vynuluje v matici cisla pod diagonalou
b = np.random.rand(4)
print(A, b)
def gauss_elim_zpetny(A,b):
## DOPLŇTE ##
x = np.zeros(A.shape[0])
for i in range(A.shape[0]-1, -1, -1):
x[i] = b[i] / A[i,i]
for j in range(i+1,A.shape[1]):
x[i] -= A[i,j]*x[j] / A[i,i]
return x
print(gauss_elim_zpetny(A, b))
print(la.solve(A, b)) # kontrola
[[0.0606048 0.5326386 0.66849927 0.05845012]
[0. 0.41407579 0.25918567 0.68595236]
[0. 0. 0.43847417 0.56602285]
[0. 0. 0. 0.94479252]] [0.86302031 0.05678913 0.12134928 0.44786873]
[21.3325721 -0.43833849 -0.33517998 0.47403924]
[21.3325721 -0.43833849 -0.33517998 0.47403924]
Teď již stačí jen použít obě metody na řešení libovolné soustavy linearních rovnic:
A = np.random.rand(4,4)
b = np.random.rand(4)
print(A, b)
def gauss_elimimace(A,b):
A,b = gauss_elim_dopredna(A, b)
return gauss_elim_zpetny(A, b)
try:
np.testing.assert_array_almost_equal(gauss_elimimace(A, b), np.linalg.solve(A, b), decimal=7)
except AssertionError as E:
print(E)
else:
print("The implementation is correct.")
[[0.72458218 0.3652625 0.90447628 0.26549513]
[0.77750479 0.05504529 0.28836998 0.8341708 ]
[0.41911913 0.10566972 0.33780249 0.63693505]
[0.47983773 0.31714559 0.28555361 0.46036325]] [0.84294206 0.14118861 0.41253944 0.61167708]
The implementation is correct.
Pivoting
V této podkapitole si ukážeme několik numerických komplikací, které u Gaussovy eliminace můžou nastat.
Prvním zřejmým problémem je situace, kdy je přední prvek matice (pivot) rovný nule. Ten nemůžeme použít, protože bychom dělili při eliminaci spodních řádků nulou!
Použijte Gaussovu eliminaci gauss_elimimace() na řešení soustavy s maticí:
Vektor \(\vec{b}\) zvolte libovolně.
## DOPLŇTE ##
A = np.array([[0, 1], [1, 1]])
b = np.random.rand(2)
print(gauss_elimimace(A, b))
C:\Users\jiral\AppData\Local\Temp\ipykernel_27764\1175827558.py:13: RuntimeWarning: divide by zero encountered in long_scalars
A[j,k] -= a / A[i,i] * A[i,k]
C:\Users\jiral\AppData\Local\Temp\ipykernel_27764\1175827558.py:13: RuntimeWarning: invalid value encountered in double_scalars
A[j,k] -= a / A[i,i] * A[i,k]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In [9], line 6
3 A = np.array([[0, 1], [1, 1]])
4 b = np.random.rand(2)
----> 6 print(gauss_elimimace(A, b))
Cell In [8], line 6, in gauss_elimimace(A, b)
5 def gauss_elimimace(A,b):
----> 6 A,b = gauss_elim_dopredna(A, b)
7 return gauss_elim_zpetny(A, b)
Cell In [6], line 13, in gauss_elim_dopredna(A, b)
11 a = A[j,i]
12 for k in range(i,A.shape[1]): # zde staci prochazet indexy [i,n-1]
---> 13 A[j,k] -= a / A[i,i] * A[i,k]
14 b[j] -= a / A[i,i] * b[i]
15 return A,b
ValueError: cannot convert float NaN to integer
Gaussova eliminace nedokáže matici s nulovými prvky na diagonále převést na horní trojúhelníkovou.
Druhý problém nastává, pokud je pivot velmi malý. Tedy na diagonále matice se nachází velmi nízké hodnoty.
Použijte Gaussovu eliminaci gauss_elimimace() na řešení soustavy s maticí a pravou stranou:
Výsledek porovnejte s řešením získaným pomocí knihovní funkce scipy.linalg.solve().
## DOPLŇTE ##
A = np.array([[1e-10, 2, 3], [4, 5, 6], [7, 8, 9]])
b = np.array([1, 0.1, 0.001])
print(gauss_elimimace(A, b))
print(la.solve(A, b))
Vidíme, že dostáváme výsledek s nezanedbatelnou chybou! Podobný příklad můžete vidět zde.
Chyba vzniká zaokrouhlováním při odčítání velmi odlišných čísel. Při použití malého pivota odčítáme od hodnot v matici vysoké číslo, čímž vzníká velká chyba (výrazně větší než strojová přesnost \(\varepsilon\)).
Dalším problémem je, že malé hodnoty v matici mohou vznikat odečtením blízkých hodnot v předchozích krocích. Nasledné použití této hodnoty jako pivota vede k silnému hromadění chyb!
Předchozím problémům se lze vyhnout vhodným výběrem pivota (tzv. pivotingem). Vhodný pivot je největší dostupné číslo v absolutní hodnotě. Máme několik strategií, jak pivota vybrat:
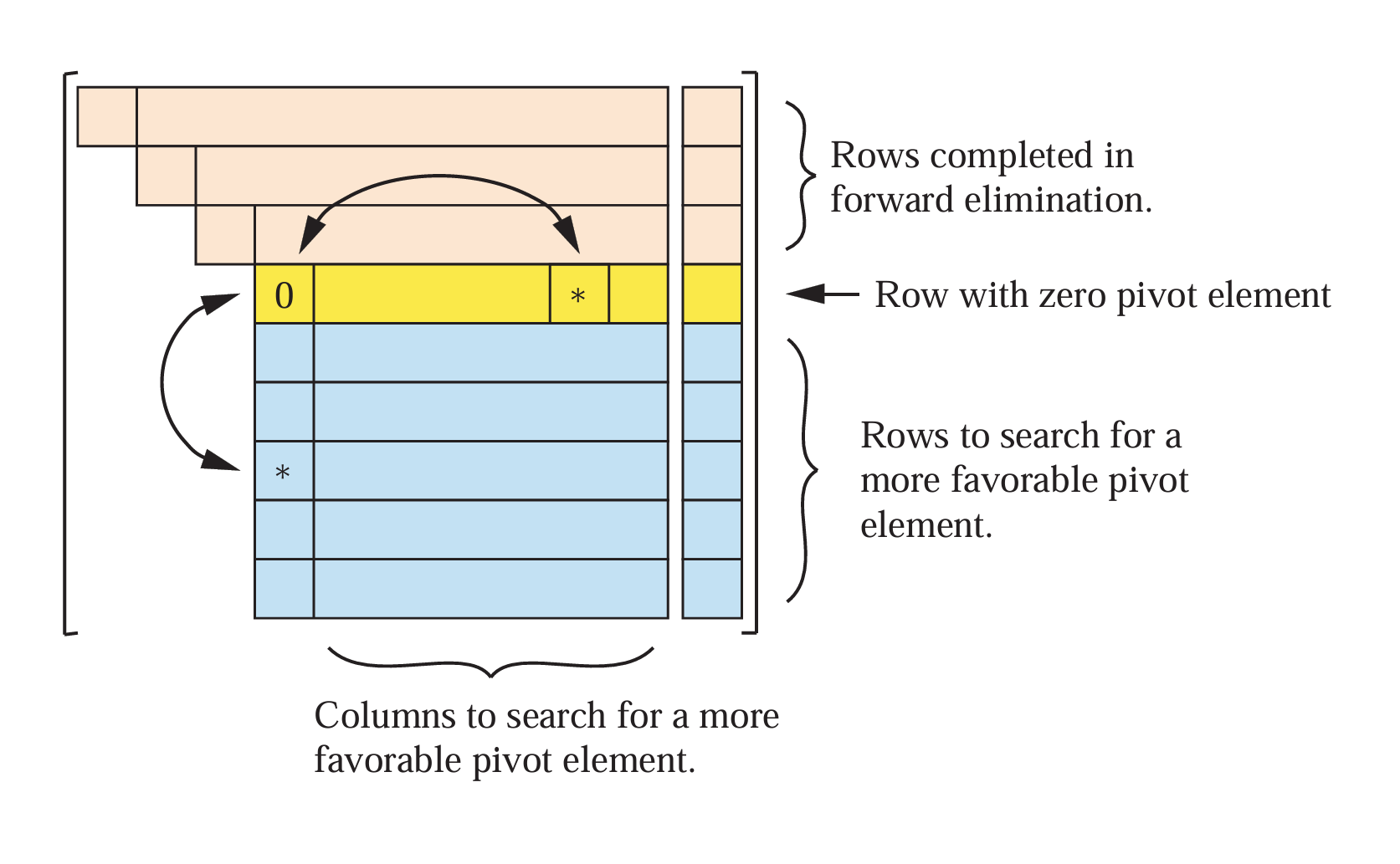
úplný pivoting - výběr z celé dosud neupravené části matice \(\max{|a_{jk}|}\) (nevýhoda: znatelně zpomaluje výpočet)
částečný pivoting - výběr v daném sloupci (sloupcový) a řádku (řádkový)
implicitní pivoting - rychlejší verze sloupcového pivotingu, při výběru je porovnána velikost prvků v daném sloupci normovaném na maximum z prvků v jednotlivých řádcích původní matice
Při výběru pivota z jiného řádku je třeba prohodit odpovídající řádky a pravou stranu. V případě volby pivota v jiném sloupci je třeba prohodit navíc složky hledaného řešení.
V praxi většinou stačí částečný nebo i sloupcový pivoting.
Modifikujte Gaussovu eliminační metodu pomocí tak, že použijete sloupcový pivoting. Ověřte zlepšení přesnosti na řešení předcházející soustavy rovnic. Stačí upravit zpětný chod gauss_elim_dopredna().
Pro nalezení největšího prvku se může hodit funkce np.argmax(). Pro prohození řádků lze použít np.copy() (pro uložení přepisovaného řádku do pomocné proměné) nebo pokročilého Numpy řezu A[[i,j],:] = A[[j,i],:] (prohodí řádky \(i,j\)).
A = np.array([[1e-10, 2, 3], [4, 5, 6], [7, 8, 9]])
b = np.array([1, 0.1, 0.001])
def gauss_elim_dopredna_pivoting(A, b):
A = A.copy()
b = b.copy()
## DOPLŇTE ##
for i in range(A.shape[0]):
# vyber pivota
p = np.argmax(np.abs(A[i:,i])) + i
print(p)
# swap - prohozeni radku
arr = A[p, :].copy()
A[p,:] = A[i, :]
A[i,:] = arr
arr = b[p].copy()
b[p] = b[i]
b[i] = arr
print(A,b)
# eliminace
for j in range(i+1,A.shape[0]):
a = A[j,i]
for k in range(0,A.shape[1]):
A[j,k] -= a / A[i,i] * A[i,k]
b[j] -= a / A[i,i] * b[i]
print(A,b)
return A,b
def gauss_elimimace_pivoting(A,b):
A,b = gauss_elim_dopredna_pivoting(A, b)
return gauss_elim_zpetny(A, b)
print(gauss_elimimace_pivoting(A, b))
print(la.solve(A, b))
Gauss-Jordanova eliminace#
Matici \(\mathbb{A}\) převedeme na tvar, kdy jsou na hlavní diagonále samé jedničky
Touto metodou lze získat i inverzní matici \(\mathbb{A}^{-1}\)
Thomasův algoritmus#
Pro speciální typy matic existují efektivnější algoritmy, které najdou řešení ve výrazně kratším čase. Příkladem je soustava s tridiagonální maticí. Pro takovou matici nemusíme provádět celou Gaussovu eliminaci, ale jen výrazně redukovaný počet kroků (stačí eliminovat pouze vedlejší diagonály).
Systém \( \mathbb{A} \vec{x} = \vec{b} \) s tridiagonální maticí \( \mathbb{A} \) lze efektivně řešit pomocí Thomasova algoritmu. Tridiagonální matici \( \mathbb{A} \) můžeme reprezentovat pomocí tří vektorů \( \vec{p} \), \( \vec{q} \), and \( \vec{r} \) následovně:
kde \( p_{n-1} = 0 \) and \( r_0 = 0 \). Řešení \( \mathbb{A} x = b \) získáme zpětným během eliminace:
kde koeficienty \( \mu_i \) a \( \rho_i \) jsou získány při dopředném běhu:
kde \( \mu_0 = -p_0 \, / \, q_0 \), \( \rho_0 = b_0 \, / \, q_0 \) a \(\mu_{n-1}=0\).
Implementujte Thomasův algoritmus pomocí uvedených vzorců. Nejprve je třeba provést dopředný běh (výpočet \(\mu\) a \(\rho\)) a následně zpětný běh. Správnost ověřte pomocí knihovní funkce scipy.linalg.solve().
A = np.triu(np.tril(np.random.rand(5, 5), 1), -1)
b = np.random.rand(5)
print(A,b)
def thomas_alg(A,b):
## DOPLŇTE ##
mu = np.zeros(A.shape[0])
rho = np.zeros(A.shape[0])
x = np.zeros(A.shape[0])
# dopřený běh
mu[0] = -A[0,1]/A[0,0]
rho[0] = b[0]/A[0,0]
for i in range(1,A.shape[0]):
if i < A.shape[0]-1:
mu[i] = -A[i,i+1] / (A[i,i-1]*mu[i-1] + A[i,i])
rho[i] = (b[i] - A[i,i-1]*rho[i-1]) / (A[i,i-1]*mu[i-1] + A[i,i])
mu[-1] = 0
# zpětný běh
x[-1] = rho[-1]
for i in range(A.shape[0]-2,-1,-1):
x[i] = mu[i]*x[i+1] + rho[i]
return x
print(thomas_alg(A, b))
print(la.solve(A,b))
LU dekompozice#

LU dekompozice rozděluje matici na součin spodní a hodní trojúhelníkové matice. Lze ji spočítat pomocí Croutova algoritmu:
pro všechna \(j = 1, 2, \dots, n\).
Tento algoritmus má podobnou složitost jako Gaussova eliminace. Je výhodný v případě, kdy řešíme stejnou soustavu rovnic pro mnoho různých pravých stran. V takovém případě by se nevyplatilo provádět Gaussovu eliminaci pořád znova. Naopak, pokud matici rozložíme pomocí LU dekompozice, stačí provést dvakrát zpětný běh Gaussovy eliminace, který je pouze \(O(n^2)\) oproti Gaussově eliminaci \(O(n^3)\)! Matematicky stačí vyřešit:
Iterativní zpřesnění řešení#
Další výhodou je možnost rychlého iterativního zpřesnění řešení. Uvažujme nepřesné řešení \(\vec{x}^{\prime}\) soustavy \(\mathbb{A} \vec{x} = \vec{b}\):
Tedy počáteční nepřesné řešení \(\vec{x}_0\) můžeme nepřesné řešení iterativně zpřesňovat pomocí:
Pro velké matice (\(N > 50\)) již dochází v přímých metodách k výraznému kumulování zaokrouhlovacích chyb, jelikož počet aritmetických operací roste s \(O(N^3)\). Obzvlášť u matic blízkých singulární matici (lineární závislost řádků) je chyba významně zesilována. Proto je doporučeno využít iterativního zpřesnění, což umožní snížit chybu zpět na strojovou přesnost. Zároveň si tím nepokazíme celkovou složitost, jelikož prvotní řešení soustavy zabere \(O(N^3)\), zatímco jedna iterace zpřesnění má složitost již jen \(O(N^2)\)!
Pro singulární matice nebo blízké singulární můžou přímé, které jsme v této kapitole viděli, snadno selhat. Existují proto specializované SVD metody (Singular Value Decomposition), které si dokáží poradit s obdélníkovými maticemi a maticemi se soustavami s závislými rovnicemi.